
画像の質を上げてみよう
前回書いた記事、「【機械学習③】TensorFlowのチュートリアルにあるオートエンコーダのデータセットをFashion-MNISTからCIFAR-10にしてみた」で出力された画像は、とても粗い状態でした。


そこで今回は、出力される画像の質を向上させるために試行錯誤した過程について、書いていきます。
アプローチ①〜オートエンコーダの多層化〜
多層化するとは?
まずは、オートエンコーダの多層化を行いたいと思います。
層を増やすことで、「重み(パラメータ)」の数を増やし、ニューラルネットワーク全体の表現力を高めることを狙います。
今回は、2層、3層と層を増やしていった時に、それぞれどのように変化するか比較したいと思います。なお、「モデル設計」に関わるところ以外のコードは、「【機械学習③】TensorFlowのチュートリアルにあるオートエンコーダのデータセットをFashion-MNISTからCIFAR-10にしてみた」の記事に記載したものと同一であるため、解説は省いて、全体のコードのみ以下に示すこととします。
全体のコード
以下のコードはGoogle Colaboratory上での実行を想定しています。ランタイムのタイプを「GPU」に変更すると、モデルの学習時間が短くなるのでおすすめです。
# ライブラリのインポート
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
import pandas as pd
import keras
from keras import layers, losses
from keras.datasets import cifar10
from keras.models import Model
# ============================================================
# 日本語でラベル付け
(x_train, y_train), (x_test, y_test) = cifar10.load_data() #
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
cifar10_labels = np.array(['飛行機','自動車','鳥','猫','鹿','犬','蛙','馬','船','トラック'])
# ============================================================
# モデルの設計と、設計したモデルのインスタンス作成
#
# ここで、2層、3層のモデル設計を行います。
########################################
# 以下の章で記載されるコードを実行して下さい。#
########################################
#
# ============================================================
#モデルの学習
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())
autoencoder.fit(x_train, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))
# ============================================================
# 元画像とオートエンコーダの出力画像を表示
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()
# 画像表示数
n = 10
# 画像番号[0〜(9999-n)]
m = 0
plt.figure(figsize=(20, 4))
for i in range(n):
# 元画像の表示
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[m+i])
plt.title(cifar10_labels[y_test[m+i][0]] + " 元画像")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 再構築画像の表示
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[m+i])
plt.title("再構築")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()2層の時
モデル設計
2層の時のモデル設計は以下の通りです。
latent_dim = 512
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = keras.Sequential([
layers.Flatten(),
layers.Dense(1024, activation='relu'), #この層を追加
layers.Dense(latent_dim, activation='relu'),
])
self.decoder = keras.Sequential([
layers.Dense(512, activation='relu'), #この層を追加
layers.Dense(32*32*3, activation='sigmoid'),
layers.Reshape((32, 32, 3))
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder(latent_dim)画像出力結果
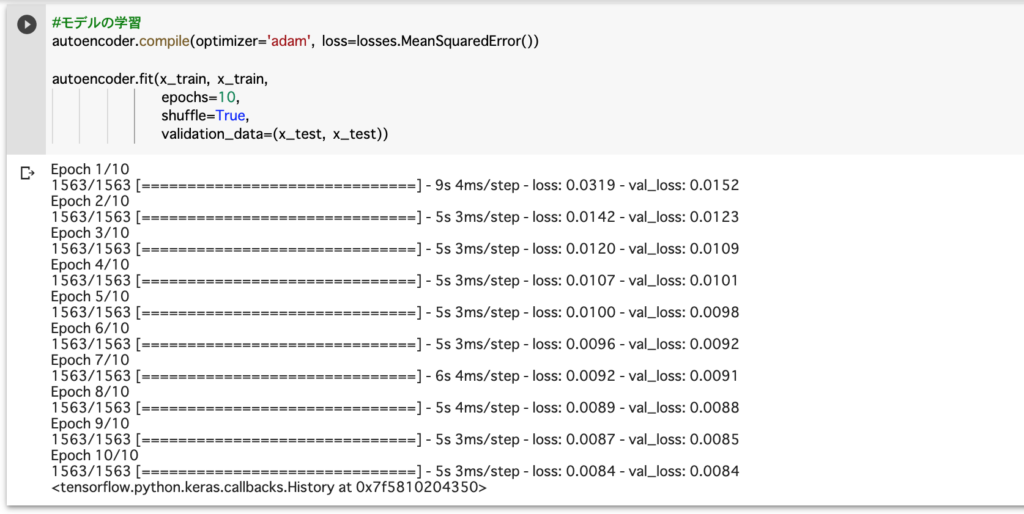
2層の時の出力画像は以下の通りです。

うーん・・・。画像は粗いままですね。
val_loss(validation loss)の値は0.0084です。val_lossの値が小さいほど、画質が良いことを示しています。
「【機械学習③】TensorFlowのチュートリアルにあるオートエンコーダのデータセットをFashion-MNISTからCIFAR-10にしてみた」で実行した時は、val_lossの値が0.0090でしたので、ごく僅かに改善しているようですが、パッと見では違いがほとんど分からない程度です。
3層の時
モデル設計
3層の時のモデル設計は以下の通りです。
latent_dim = 512
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = keras.Sequential([
layers.Flatten(),
layers.Dense(3072, activation='relu'), #この層を追加
layers.Dense(1024, activation='relu'), #この層を追加
layers.Dense(latent_dim, activation='relu'),
])
self.decoder = keras.Sequential([
layers.Dense(512, activation='relu'), #この層を追加
layers.Dense(1024, activation='relu'), #この層を追加
layers.Dense(32*32*3, activation='sigmoid'),
layers.Reshape((32, 32, 3))
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder(latent_dim)画像出力結果
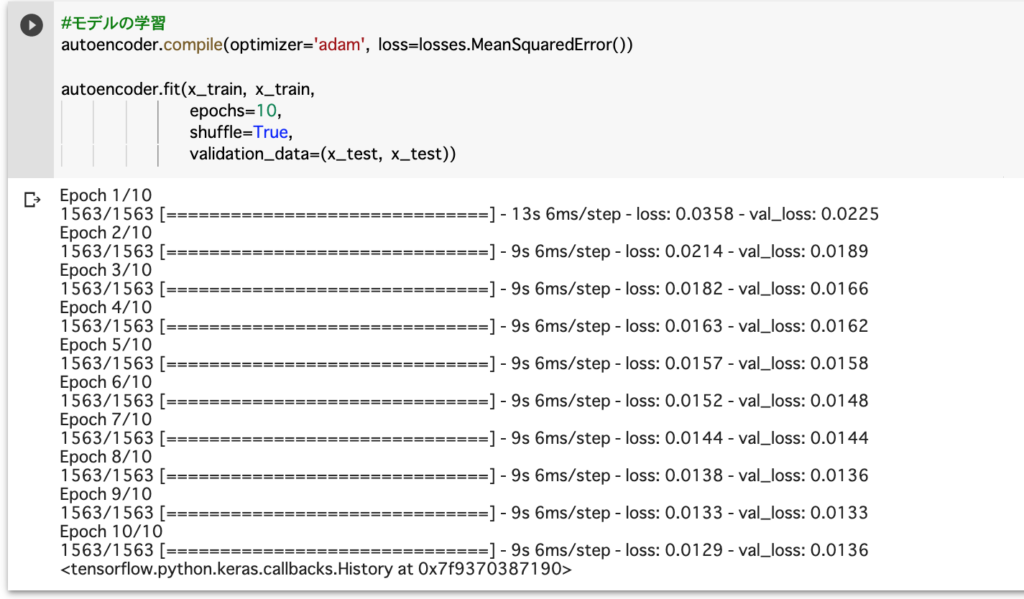
3層の時の出力画像は以下の通りです。

画像の質は最初よりも良くなっているどころか、むしろ悪化してしまいました。
val_lossの値も0.0136と、最初より悪くなっています。
なぜ画像は粗くなったのか?
2層にした時は、val_lossの値が0.0090から0.0084と、僅かながら改善していたのに、なぜ3層の時は0.0136とむしろ悪化してしまったのでしょうか?
これは、層を深くしたことにより勾配消失が起こり、誤差逆伝播(バックプロパゲーション)がうまくはたらかず、学習が適切にできなかったと考えられます。
アプローチ②〜「畳み込み」オートエンコーダ〜
「畳み込み」オートエンコーダとは?
次は、畳み込みオートエンコーダを試してみたいと思います。
畳み込みオートエンコーダとは、畳み込み層を用いたオートエンコーダのことです。畳み込み層は、KerasではConv2D, Conv2DTransposeレイヤーとして実装されています。
それでは、エンコーダとしてConv2Dレイヤーを、デコーダとしてConv2DTransposeレイヤーを使う事により、「畳み込み」オートエンコーダを実行して画質が向上するか確認を行います。
モデル設計以外のコードは、多層化と同様です。
モデル設計
畳み込みオートエンコーダの時のモデル設計は以下の通りです。
class Autoencoder_Conv(Model):
def __init__(self):
super(Autoencoder_Conv, self).__init__()
self.encoder = keras.Sequential([
layers.Input(shape=(32, 32, 3)),
layers.Conv2D(16, (3,3), activation='relu', padding='same', strides=2),
layers.Conv2D(8, (3,3), activation='relu', padding='same', strides=2)])
self.decoder = keras.Sequential([
layers.Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
layers.Conv2D(3, kernel_size=(3,3), activation='sigmoid', padding='same')])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
autoencoder = Autoencoder_Conv()画像出力結果
畳み込みオートエンコーダの時の出力画像は以下の通りです。

出力された画像の質が、元画像とほとんど変わらない状態になりました。
val_lossの値も0.0018と、最初の0.0090と比較するとかなり改善が見られます。

畳み込みオートエンコーダにより、元画像と遜色の無い状態まで持ってくることができました。
畳み込みオートエンコーダは、画像の特徴抽出に適した構造をしているので、上手くいったのだと思います。


コメント