
概要
深層学習ライブラリTensorFlowのWebページtensorflow.orgには、オートエンコーダのチュートリアルが紹介されています。このチュートリアルに基づいて、オートエンコーダを実装してみたいと思います。

このチュートリアルでは、データセット「Fashion-MNIST」が使われています。
ただ、「Fashion-MNIST」は白黒画像なので、より視覚的に分かりやすいカラー画像の「CIFAR-10」に対応するようにコードを書き換えてみたいと思います。
なお、以下のコードはGoogle Colaboratory上での実行を想定しています。
そもそもオートエンコーダとは?
そもそもオートエンコーダとはどういったものでしょうか。独立行政法人情報処理推進機構が編集した『AI白書 2020』には、以下のように説明されています。
オートエンコーダー(Autoencoder)は2006年に発表され、今日のディープラーニング隆盛のきっかけともなった技術である。次元数を減らした(8×8のマトリクスを7×7に圧縮するなど)ニューロンの層を重ねていくことで特徴の圧縮を行うエンコーダーと逆の構造を持つデコーダーを接続したものである。エンコーダーとデコーダーの中間には、数値ベクトルである「圧縮された特徴表現」ができる。「圧縮された特徴表現」から、デコーダーを通して入力と同じ出力を再現する。オートエンコーダーは、入力情報と同じ出力情報(例えば特定のネコの画像)を再現する。
なお、デコーダーに着目すると「圧縮された特徴表現」から、出力情報を生成していることになるのでGeneratorと呼ばれることがある。
独立行政法人情報処理推進機構 AI白書編集委員会 編 『AI白書 2020』

この技術は現在、「画像のノイズ除去」や、大量のネジの中から不具合のあるネジを見つけ出す「異常検知」等に役立っています。
Fashion-MNISTとは?
画像認識の機械学習を行う時、以下の3つの画像データセットがよく使われます。
・MNIST・・・手書き数字の画像データセット
・Fashion-MNIST・・・ファッション商品の白黒画像セット
・CIFAR-10・・・動物や乗り物のカラー画像セット
Fashion-MNISTは60,000枚の訓練セットと10,000枚のテストセットからなります。各サンプルは 28×28 グレースケール画像で、10クラスのラベル(Tシャツ、ドレス、バッグ等)と関連付けされています。
Fashion-MNISTについて詳しく知りたい方は、https://github.com/zalandoresearch/fashion-mnist/blob/master/README.ja.md を参考にして下さい。
今回は、このFashion-MNISTではなく、CIFAR-10を使ってオートエンコーダを実行しようと思います。CIFAR-10については、「【機械学習①】Google Colaboratoryで画像データセットCIFAR-10を表示してみた」の記事で扱ったので、参考にして下さい。

オートエンコーダの実行
ランタイムのタイプを変更
Google Colaboratoryのランタイムのタイプを「GPU」に変えると実行スピードが速くなるので、その設定を最初に行います。
「ランタイム」→「ランタイムのタイプ変更」→「ハードウェア アクセラレータ」の設定を「None」から「GPU」に変更します。

ライブラリのインポート
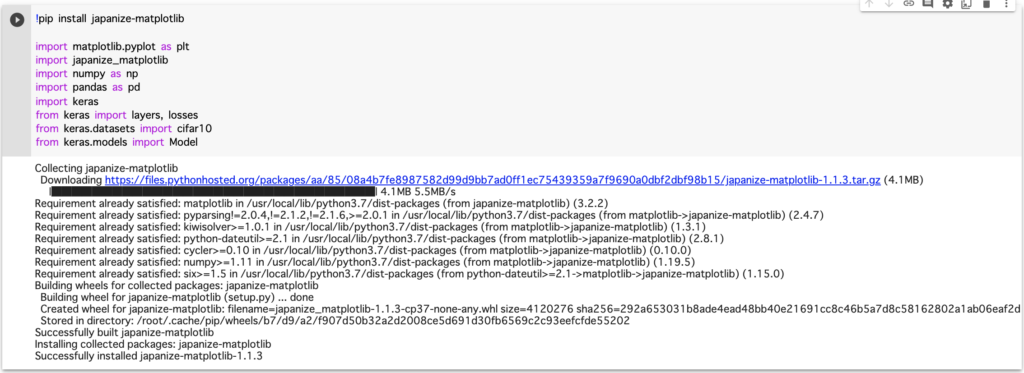
まずはライブラリをインポートします。
!pip install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
import pandas as pd
import keras
from keras import layers, losses
from keras.datasets import cifar10
from keras.models import Model以下は、Google Colaboratoryで実行した様子です。
ラベル付け
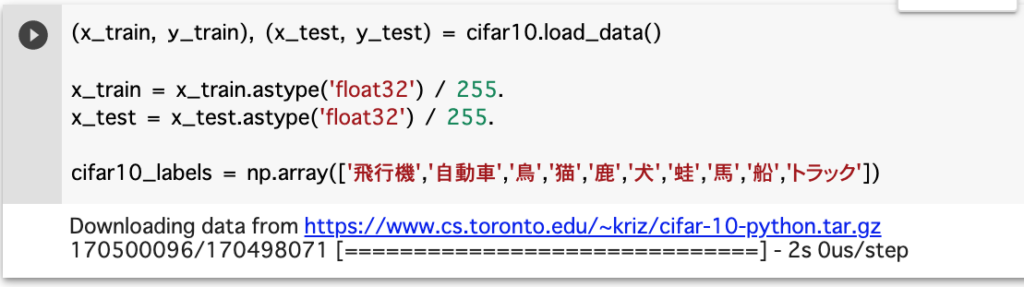
次に、日本語でラベル付けを行います。
(x_train, y_train), (x_test, y_test) = cifar10.load_data() #
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
cifar10_labels = np.array(['飛行機','自動車','鳥','猫','鹿','犬','蛙','馬','船','トラック'])以下は、Google Colaboratoryで実行した様子です。
モデルの設計
モデルの設計と、設計したモデルのインスタンスを作成します。
# 潜在空間の次元をやや大きめに設定
latent_dim = 512 #
# モデルの設計
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
self.encoder = keras.Sequential([
layers.Flatten(),
layers.Dense(latent_dim, activation='relu'),
])
self.decoder = keras.Sequential([
layers.Dense(32*32*3, activation='sigmoid'), #
layers.Reshape((32, 32, 3)) #
])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# モデルのインスタンスを作成
autoencoder = Autoencoder(latent_dim)モデルの設計なので、Google Colaboratoryで実行した時に、出力される情報はありません。
モデルの学習
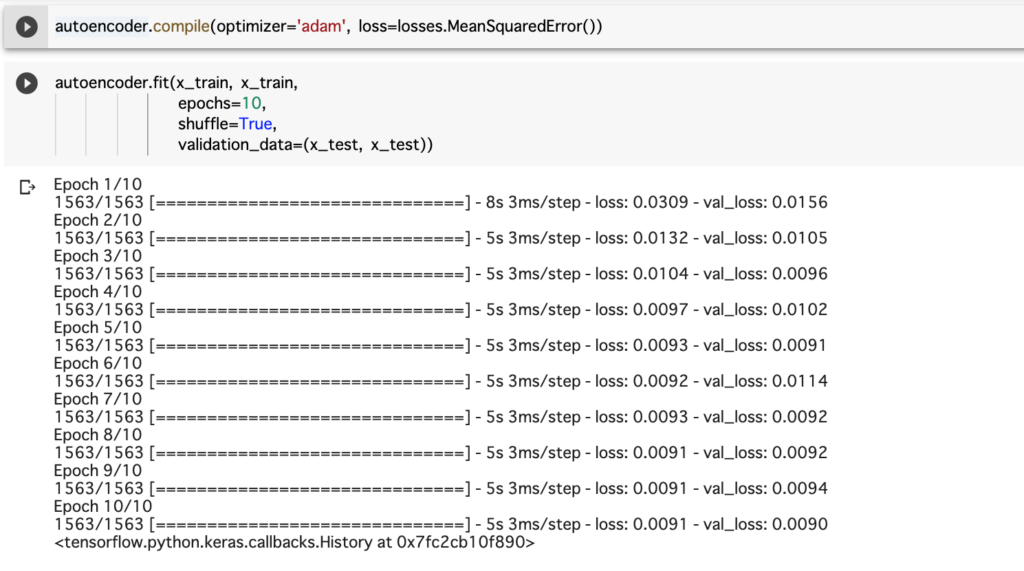
モデルの学習の方法を指定し、学習を実行します。実行が完了するまで数分かかる可能性があります。
autoencoder.compile(optimizer='adam', loss=losses.MeanSquaredError())autoencoder.fit(x_train, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))以下は、Google Colaboratoryで実行した様子です。
学習させたオートエンコーダを使ってみる
以下のコードで、元画像とオートエンコーダの出力画像を表示します。
encoded_imgs = autoencoder.encoder(x_test).numpy()
decoded_imgs = autoencoder.decoder(encoded_imgs).numpy()# 画像表示数
n = 10
# 画像番号[0〜(9999-n)]
m = 0
plt.figure(figsize=(20, 4))
for i in range(n):
# 元画像の表示
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[m+i])
plt.title(cifar10_labels[y_test[m+i][0]] + " 元画像")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 再構築画像の表示
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[m+i])
plt.title("再構築")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()以下は、Google Colaboratoryで実行した様子です。

画像は以下のように表示されました。

出力された画像の質はあまり良くありませんね・・・。
次回は、出力画像の質を高めていく過程について記事を書きたいと思います。


コメント